
Sinds de komst van Record Triggered Flows was ik meteen een enthousiast voorstander van zo snel mogelijk alle Workflow Rules en Process Builder processen migreren naar Flows. Niet met de automatische tools van Salesforce, maar van de gelegenheid gebruik makende om beginnersfouten eruit te halen, nieuwe mogelijkheden te gebruiken en vooral ook om meerdere processen op hetzelfde object samen te voegen in één Record Triggered Flow.
De gedachte daarachter was het aantal flows laag te houden waardoor je gemakkelijker overzicht houdt over welke flow de oorzaak van een gevolg kan zijn dat je wilt onderzoeken. Dit was immers mijn punt van irritatie bij Process Builder. Vaak tref ik er meerdere processen op hetzelfde object aan, is niet heel snel duidelijk te zien welke actief zijn en blijkt meestal niet duidelijk uit de naam waar ze wel en niet verantwoordelijk voor zijn.
In de praktijk blijkt echter al gauw dat met name je beperken tot één After flow per object geen houdbare strategie is. Sowieso zul je al gauw ten minste een before flow én een after flow gebruiken en om zeker te zijn waar een actie vandaan komt, moet je ze meestal toch beide onderzoeken.
Daar komt bij dat wanneer je een asynchronous of delayed path wilt gebruiken, de entry conditions van de flow specifieker zullen moeten zijn. Decision elements in een asynchronous path hebben niet dezelfde capaciteiten als het om filteren gaat als die in het directe pad. Je kunt bijvoorbeeld niet testen of een veld gewijzigd is. Bij een asynchroon gebruikte Record Triggered Flow ben je dus al gauw gedwongen om toch specifieke entry conditions te gebruiken. Dan gaat de strategie al mank, want als je voor Before Flows (Fast Field Updates) en de het Direct Path van After Flows (Actiond and Related Records) de één flow per object strategie hanteert, maar wel afzonderlijke asynschone After flows niet, is dat al werken met twee verschillende standaarden tegelijk.
Nog even snel de typen Record Triggered Flows uitgelegd:
- Fast Field Updates
- Wordt uitgevoerd vóór een record daadwerkelijk de database in gestuurd wordt.
- Een daadwerkelijk record update element erin is niet nodig. Een assignment alleen volstaat om de waarde van een veld te updaten.
- Het opslaan gebeurt sowieso al dus die opdracht hoef je niet extra te geven.
- Fast Field Updates Flows worden zelfs eerder uitgevoerd dan Apex Before Triggers
- Je kunt geen andere records dan degene die de flow triggert bewerken, maken of verwijderen.
- Je kunt wel andere records ophalen om de informatie ervan te gebruiken.
- Je kunt geen subflows gebruiken.
- Actions and Related Records
- Je kunt gebruik maken van subflows.
- Je kunt andere records maken, bewerken en verwijderen.
- Wordt uitgevoerd direct na Apex After Triggers.
- Het is mogelijk om een asynchronous path toe te voegen. Een eventuele vastloper in dat pad belemmert het opslaan van het record niet.
- Je hebt de mogelijkheid om een scheduled path toe te voegen wat een aantal minuten, uren of dagen later pas verder gaat met uitvoeren en waarbij je kunt kiezen hoeveel records er in één batch zitten.
Nu vind ik de één Before Flow strategie nog steeds niet echt slecht, maar er zijn wel keerzijden waarmee je rekening moet houden.
Allereerst zal ik daarom kort uitleggen hoe deze werkwijze in elkaar steekt.
- De flow is van toepassing op zowel created als updated, niet slechts een van de twee
- De flow als geheel heeft geen entry criteria, dus elke decision (behalve ‘sub-decisions’) wordt bij elke aangemaakte of geüpdatete record gecheckt.
- Of een bepaald deelproces van een aantal elementen wel of niet uitgevoerd wordt, bepaal je steeds met een decision.
Dit betekent dus ook dat deze flow altijd geactiveerd wordt, ook als aan de criteria van geen enkele van de beslissingen voldaan wordt. Dat is eigenlijk de manier van denken zoals we van Process Builder gewend zijn.
Belangrijker is dat op deze manier verschillende processen van dezelfde flow afhankelijk kunnen zijn. Dat kan moeilijkheden geven bij aanpassingen.
Wanneer ik voor een klant aan meerdere functionaliteiten tegelijk werk die beide een verschillende stap in dezelfde flow gebruiken, kan het zijn dat mijn aanpassingen voor story A in versie 3 van de flow nog niet geaccepteerd zijn, maar de aanpassingen die ik in versie 4 ten behoeve van story B gemaakt heb wel. Dan zou ik een nieuwe versie van de flow moeten maken met de nieuwe functionaliteit voor story B maar zonder die van story A.
Dat probleem speelt niet als story A en B beide een eigen flow gebruiken.
Je zou het als een nadeel kunnen zien dat er dan veel meer verschillende flows op hetzelfde object zullen ontstaan, maar als je in de naamgeving van de flows duidelijk bent over de entry conditions en in de beschrijving de uitwerking van de flow goed beschrijft, zul je toch zelden elke flow hoeven te openen om te weten waar een bepaalde update of foutmelding vandaan komt.
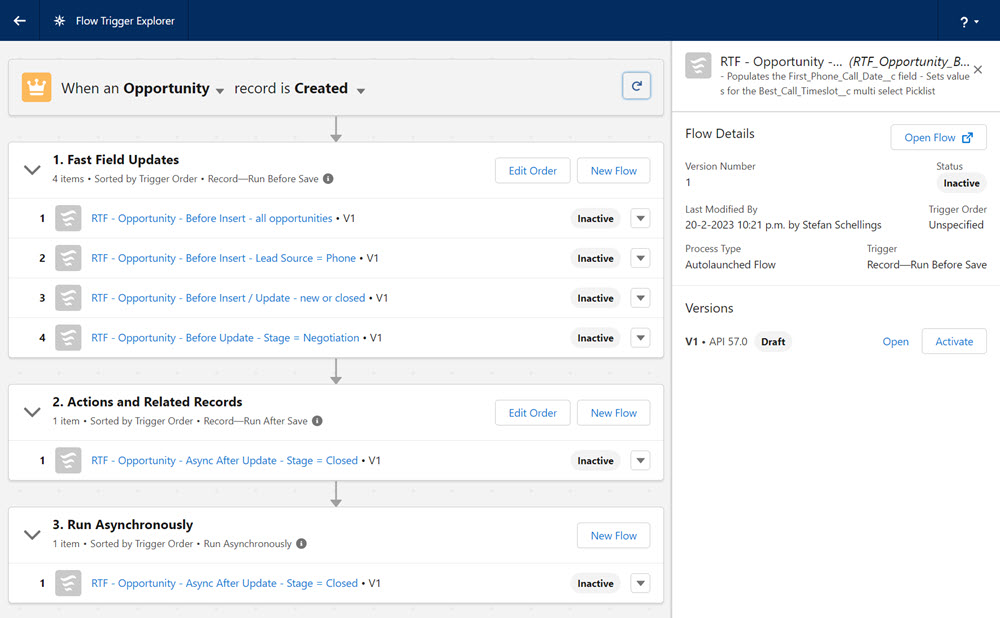
Ook kun je in de Flow Trigger Explorer heel duidelijk de volgorde waarin de verschillende flows worden uitgevoerd, bekijken, bepalen en aanpassen.
Uiteraard is er niet één ultieme best practice die in elk denkbaar en onvoorzien scenario het beste uitpakt, maar ik ben wel van mening dat de strategie met zeer specifieke flows, je org zeker overzichtelijker maakt. Schenk daarbij in het bijzonder aandacht aan een goede naming convention en zorg dat je de description altijd goed gebruikt.