
Since the introduction of Record Triggered Flows, I immediately became an enthusiastic advocate for migrating all Workflow Rules and Process Builder processes to Flows as quickly as possible. Not using Salesforce's automatic migration tools, but taking the opportunity to eliminate beginner mistakes, leverage new capabilities, and especially to consolidate multiple processes on the same object into a single Record Triggered Flow.
The underlying idea was to keep the number of flows low, making it easier to track which flow could be the cause of a desired outcome that needs investigation. This was, after all, my point of frustration with Process Builder. Often, I encounter multiple processes on the same object, making it not immediately clear which ones are active, and their purpose is usually not evident from their names.
However, in practice, it quickly becomes apparent that limiting yourself to just one After flow per object is not a sustainable strategy. In any case, you will soon need at least one Before flow and one After flow, and to be sure of the origin of an action, you usually need to examine both.
Additionally, when using an asynchronous or delayed path, the entry conditions of the flow need to be more specific. Decision elements in an asynchronous path do not have the same filtering capabilities as those in the direct path. For example, you cannot test if a field has changed. When using a Record Triggered Flow with an asynchronous path, you are therefore quickly forced to use specific entry conditions. This undermines the strategy because if you adhere to the "one flow per object" strategy for Before Flows (Fast Field Updates) and the Direct Path of After Flows (Actions and Related Records), but not for separate asynchronous After flows, you are working with two different standards.
Let's quickly explain the types of Record Triggered Flows:
- Fast Field Updates
- Executed before a record is actually sent to the database.
- An actual record update element is not necessary. An assignment is sufficient to update the value of a field.
- The saving process already happens automatically, so you don't need to give an extra command for it.
- Fast Field Updates Flows are even executed before Apex Before Triggers
- You cannot edit, create, or delete other records than the one triggering the flow
- However, you can retrieve other records to use their information
- Subflows cannot be used
- Actions and Related Records
- Subflows may be embedded
- It is possible to You can create, edit, and delete other records thena the one that triggered the flow interview
- Executed immediately after Apex After Triggers
- It is possible to add an asynchronous path. Any potential errors in that path will not prevent the record from being saved.
- There is an option to add a scheduled path that continues execution a certain number of minutes, hours, or days later, allowing you to choose the batch size
I still don't think the "one Before Flow" strategy is necessarily bad, but there are downsides to consider.
First of all, let me briefly explain how this approach works.
- The flow applies to both created and updated records, not just one of them.
- The flow as a whole does not have entry criteria, so every decision (except for 'sub-decisions') is checked for every created or updated record.
- Whether a particular sub-process consisting of multiple elements is executed or not is determined by a decision element.
This means that this flow is always activated, even if none of the decision criteria are met. This is actually how Process Builder processes always work.
More importantly, this approach allows different processes to be dependent on the same flow. This can create difficulties when making adjustments.
When working on multiple functionalities for a client simultaneously, where each functionality uses a different step in the same flow, it's possible that my adjustments for story A in version 3 of the flow may not have been accepted yet, while the adjustments I made for story B in version 4 have been accepted. In that case, I would have to create a new version of the flow with the new functionality for story B but without that of story A.
This problem doesn't arise if both story A and story B rely on their own separate flow.
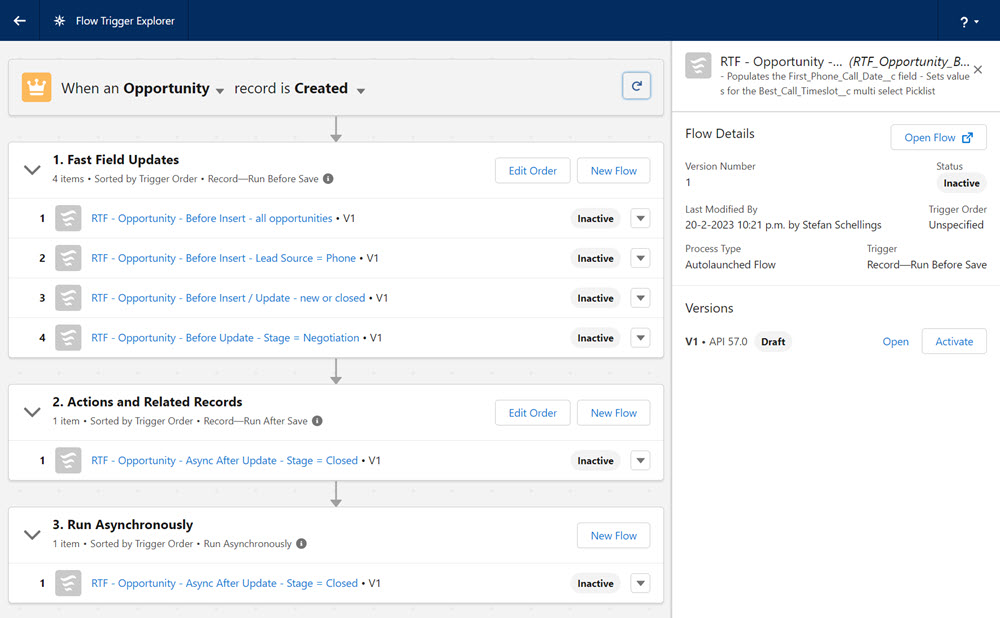
You could see it as a disadvantage that this approach leads to a larger number of different flows on the same object. However, if you are clear about the entry conditions in the naming of the flows and describe the flow's purpose in the description, you will rarely need to open each flow to determine the source of a specific update or error message.
Additionally, in the Flow Trigger Explorer, you can easily view, determine, and modify the order in which the different flows are executed.
Of course, there is no single ultimate best practice that works best in every imaginable and unforeseen scenario. However, I do believe that the strategy of using highly specific flows makes your org more organized. Pay particular attention to a good naming convention and make sure to use the description effectively.